Skip to main content
Skip to main content
 Rapita Systems Collaborates with Wind River to Break the Multicore Certification Barrier
Rapita Systems Collaborates with Wind River to Break the Multicore Certification Barrier
 Rapita Systems Launches Next Generation of MACH178 for Multicore
Rapita Systems Launches Next Generation of MACH178 for Multicore
 RVS 3.24 accelerates multicore software verification
RVS 3.24 accelerates multicore software verification
 Rapita Systems and Avionyx Announce Strategic Partnership to Offer Best-in-class Avionics Solutions
Rapita Systems and Avionyx Announce Strategic Partnership to Offer Best-in-class Avionics Solutions
 The Evolution of DO 178 and ED-12 Standards
The Evolution of DO 178 and ED-12 Standards
 Retro gaming with the Sim68020
Retro gaming with the Sim68020
 RVS gets a new timing analysis engine
RVS gets a new timing analysis engine
 How to measure stack usage through stack painting with RapiTest
How to measure stack usage through stack painting with RapiTest
 How to achieve multicore DO-178C certification with Rapita Systems
How to achieve multicore DO-178C certification with Rapita Systems
 How to achieve DO-178C certification with Rapita Systems
How to achieve DO-178C certification with Rapita Systems
 Certifying Unmanned Aircraft Systems
Certifying Unmanned Aircraft Systems
 DO-278A Guidance: Introduction to RTCA DO-278 approval
DO-278A Guidance: Introduction to RTCA DO-278 approval
 DO-178C Multicore Virtual Training
DO-178C Multicore Virtual Training
 HISC 2026
HISC 2026










This week our series of blog posts on optimizing embedded software with the aim of improving (i.e. reducing) worst-case execution times takes an in-depth look at loops inside functions/inlining.
Software optimization techniques which improve worst-case execution times #4: Loops Inside Functions / Inlining
It is common to find worst-case hotspots that consist of a loop that iterates a large number of times with calls to one or more simple functions within the loop. Here the overhead of making the function call, comprising instructions to save and restore registers and jump to the called function, may make a significant contribution to the overall execution time.
In this case, it is often worthwhile restructuring the code, moving the loop inside the function, or moving the code for the sub-function up into the calling function (in-lining). This reduces the number of function calls saving the function call overhead.
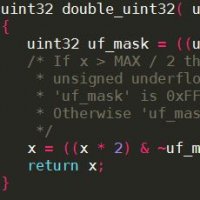
Example: Function in-lining
void
swap(Uint32 *a, Uint32 k, Uint32 j)
{
Uint32 tmp;
tmp = a[k];
a[k] = a[j];
a[j] = tmp;
}
void
ripple_swap(Uint32 *a, Uint32 length)
{
Uint32 i,j,k;
for(i=length - 1; i>0; i--)
{
for(j=0; j<i; j++)
{
k = j+1;
if(a[j] > a[k])
{
swap(a, k, j);
}
}
}
}
In the alternative ripple sort example above, the nested for loops sort the contents of the array a[] into order, smallest value first. If two elements of the array are out of order, then the function swap() is called to exchange the two values. In the worst-case, swap() is called n(n+1)/2 times to sort an array of n values.
The more efficient implementation method is to simply in-line the code for the swap() function. The worst-case execution times of the two different implementations were as follows:
| Function | WCET (clock ticks) | |
| MPC555 | HC12 | |
| ripple_swap | 1717 | 9678 |
| ripple32 | 1050 | 7775 |
| Reduction in WCET | 38.8% | 19.6% |
Note, these figures assume a maximum array length of 10.
Alternatively, the function call overhead could be removed using an inline directive to instruct the compiler to inline the code for swap(). (Note with the –O2 option used for compilation on the MPC555, the compiler does not automatically perform function in-lining).
Next week: Loop jamming
DO-178C webinars
White papers

Mitigation of interference in multicore processors for A(M)C 20-193

Developing DO-178C and ED-12C-certifiable multicore software

Efficient Verification Through the DO-178C Life Cycle

A Commercial Solution for Safety-Critical Multicore Timing Analysis