 Skip to main content
Skip to main content
 Rapita Systems Collaborates with Wind River to Break the Multicore Certification Barrier
Rapita Systems Collaborates with Wind River to Break the Multicore Certification Barrier
 Rapita Systems Launches Next Generation of MACH178 for Multicore
Rapita Systems Launches Next Generation of MACH178 for Multicore
 RVS 3.24 accelerates multicore software verification
RVS 3.24 accelerates multicore software verification
 Rapita Systems and Avionyx Announce Strategic Partnership to Offer Best-in-class Avionics Solutions
Rapita Systems and Avionyx Announce Strategic Partnership to Offer Best-in-class Avionics Solutions
 The Evolution of DO-178 and ED-12 Standards
The Evolution of DO-178 and ED-12 Standards
 Retro gaming with the Sim68020
Retro gaming with the Sim68020
 RVS gets a new timing analysis engine
RVS gets a new timing analysis engine
 How to measure stack usage through stack painting with RapiTest
How to measure stack usage through stack painting with RapiTest
 How to achieve multicore DO-178C certification with Rapita Systems
How to achieve multicore DO-178C certification with Rapita Systems
 How to achieve DO-178C certification with Rapita Systems
How to achieve DO-178C certification with Rapita Systems
 Certifying Unmanned Aircraft Systems
Certifying Unmanned Aircraft Systems
 DO-278A Guidance: Introduction to RTCA DO-278 approval
DO-278A Guidance: Introduction to RTCA DO-278 approval
 DO-178C Multicore Virtual Training
DO-178C Multicore Virtual Training
 HISC 2026
HISC 2026










Execution time and response time are two concepts which are sometimes mistakenly conflated. In this post, I will make the distinction between the two clear and explain why both concepts are important in real-time embedded systems design.
First, some terminology. A task is a piece of code that is to be run within a single thread of execution. A task issues a sequence of jobs to the processor which are queued and executed.
The time spent by the job actively using processor resources is its execution time. The execution time of each job instance from the same task is likely to differ.
Common sources of variation are path data dependencies (the path taken through the code depends on input parameters) and hard-to-predict hardware features such as branch prediction, instruction pipelining and caches.
The response time for a job is the time between when it becomes active (e.g. an external event or timer triggers an interrupt) and the time it completes. Several factors can cause the response time of a job to be longer than its execution time - Figure 1 shows some of these:
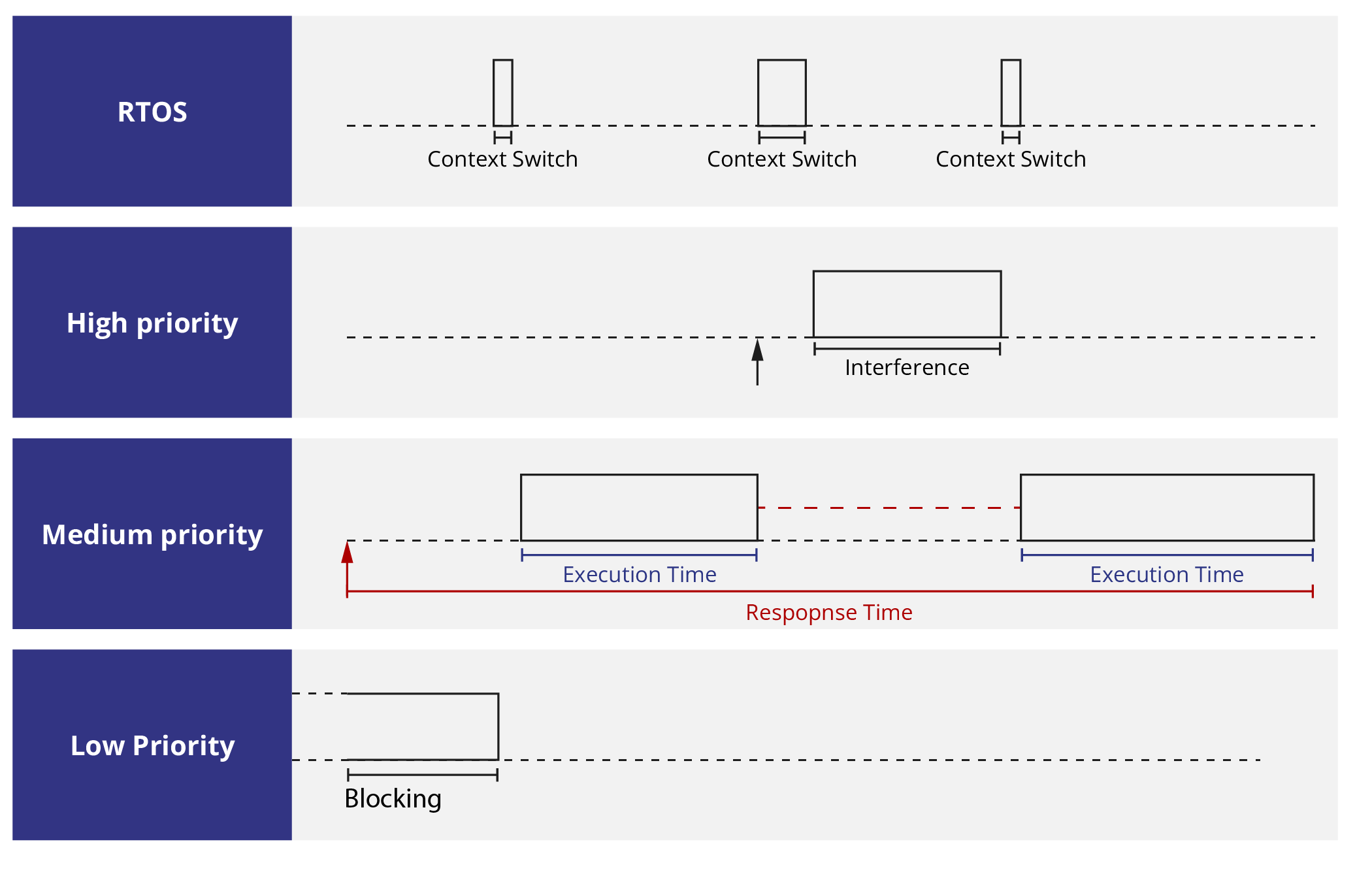
In Figure 1, jobs in the queue are scheduled using fixed priority pre-emptive scheduling. Execution and response times are shown for the medium priority job. The real-time operating system (RTOS) scheduler always selects the highest priority job that is ready to run next. A job is suspended if a higher priority one becomes active, and resumes after all higher priority jobs have completed.
A lower priority job can also prevent a job from running if it locks a shared resource before the higher priority job does. This is called priority inversion. RTOS overheads for context switches and pre-emptions will also delay a job. These may be very small with appropriate hardware support. Release jitter caused by insufficient clock granularity is another source of delay (not shown above) [1].
Both execution times and response times are of interest to real-time systems designers. This is usually in the context of worst-case execution times (WCETs) and worst-case response times (WCRTs). High level system requirements will specify maximum response times for a task, known as a deadline. WCRTs are calculated using response time analysis, which takes WCETs and a scheduling policy as inputs. This may lead to execution time budgets and a scheduling policy being derived as lower level requirements.
Being able to measure response times and execution times individually is important. If response times are measured but execution times are not, then it is not possible to perform worst-case response time analysis. This runs the risk of the system missing a deadline because a particular job sequence / job execution time combination was not encountered in testing. Response time measurement data is still useful, however, for knowing how close jobs are to missing deadlines.
And finally… in certain circumstances execution time increases may even lead to response time decreases! Using our diagram once again, imagine that a previous job of the high priority task ran until just after the activation of the medium priority task. The low priority task which blocked the medium priority one would not be allowed to execute, allowing the medium priority task to both start and complete earlier. We suggest Baruah and Burns' paper[2] on sustainable scheduling analysis as further reading.
[1] Neil Audsley, Iain Bate and Alan Burns, "Putting fixed priority scheduling theory into engineering practice for safety critical applications", In Proceedings of the 2nd IEEE Real-Time Technology and Applications Symposium (RTAS '96), pages 2-10, 1996.
[2] Sanjoy Baruah and Alan Burns, "Sustainable Scheduling Analysis", In Proceedings of the 27th IEEE International Real-Time Systems Symposium (RTSS 2006), pages 159-168, 2006.
DO-178C webinars
White papers

Mitigation of interference in multicore processors for A(M)C 20-193

Developing DO-178C and ED-12C-certifiable multicore software

Efficient Verification Through the DO-178C Life Cycle

A Commercial Solution for Safety-Critical Multicore Timing Analysis



