Skip to main content
Skip to main content
 Rapita System Announces New Distribution Partnership with COONTEC
Rapita System Announces New Distribution Partnership with COONTEC
 Rapita partners with Asterios Technologies to deliver solutions in multicore certification
Rapita partners with Asterios Technologies to deliver solutions in multicore certification
 SAIF Autonomy to use RVS to verify their groundbreaking AI platform
SAIF Autonomy to use RVS to verify their groundbreaking AI platform
 RVS gets a new timing analysis engine
RVS gets a new timing analysis engine
 How to measure stack usage through stack painting with RapiTest
How to measure stack usage through stack painting with RapiTest
 What does AMACC Rev B mean for multicore certification?
What does AMACC Rev B mean for multicore certification?
 How emulation can reduce avionics verification costs: Sim68020
How emulation can reduce avionics verification costs: Sim68020
 How to achieve multicore DO-178C certification with Rapita Systems
How to achieve multicore DO-178C certification with Rapita Systems
 How to achieve DO-178C certification with Rapita Systems
How to achieve DO-178C certification with Rapita Systems
 Certifying Unmanned Aircraft Systems
Certifying Unmanned Aircraft Systems
 DO-278A Guidance: Introduction to RTCA DO-278 approval
DO-278A Guidance: Introduction to RTCA DO-278 approval
 The EVTOL Show
The EVTOL Show
 NXP's MultiCore for Avionics (MCFA) Conference
NXP's MultiCore for Avionics (MCFA) Conference
 Embedded World 2026
Embedded World 2026
 XPONENTIAL 2026
XPONENTIAL 2026










Worst-case execution time (WCET) analysis is critical for the verification of safety-critical real-time embedded systems. This analysis is typically performed by instrumenting source code and obtaining timing data from an instrumented build. While this is a robust method for determining WCET metrics, it requires that instrumentation be added to source code, increasing overhead. This is why we have been developing RapiTime, our on-target timing analysis tool, to perform WCET analysis with zero instrumentation.
In our RapiTime Object Code Analyser (ROCA) project, as the name implies, we have been developing a tool that lets us use object code to perform timing analysis with RapiTime. Instead of having to rely on instrumentation to obtain timing metrics, our tool uses branch trace information collected from the CPU during program execution. This lets us eliminate instrumentation overhead entirely when performing timing analysis.
We recently completed the ROCA project, and will be taking the technology further in our current SECT-AIR project. In this post, we’d like to share some details on one of the main difficulties analyzing object code presented us with: tracing control flow.
Object code control flow
We need to know the control flow of a program to determine WCET metrics from it. While a control flow graph can easily be determined from source code, it is a little more difficult to do this from object code. To trace control flow from object code, we use branch trace information to map each assembly instruction to its origin in the source code. This lets us present the program as a call tree, and each function as a loop nesting tree, and these trees are necessary for our analysis (Figure 1).
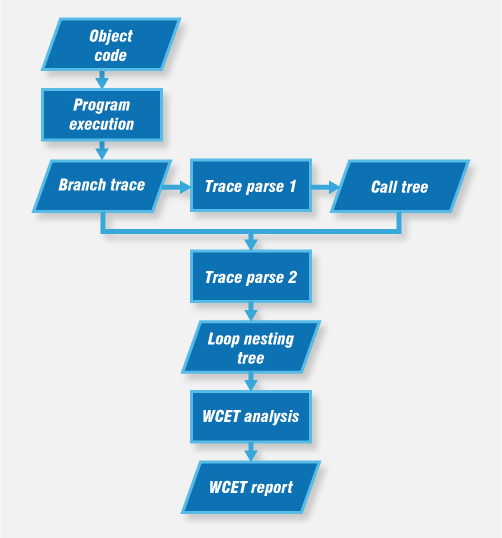
Figure 1. Using branch trace information to determine WCET.
Working out how to map assembly instructions to the source code proved to be no easy task, however. One of the main reasons for this is that object code is unstructured due to the number of “jump” instructions it contains.
Jump instructions in object code
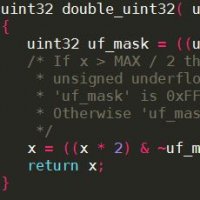
In source code, the use of conditionals, loops and function calls is the most frequently used method to affect program control flow. Object code, however, mainly executes control flow using “jump” instructions. Compare this for loop written in C with its object code when compiled for x86:
Source code
void loop_example (void)
{
for (i = 0; i < 10; i++) {
state_machine();
}
}
Object code
loop_example: movl $0, i iteration: call state_machine movl i, %eax addl $1, %eax cmpl $9, %eax movl %eax, i jle iteration ret
You may notice that the for loop has been compiled as a “jump” instruction jle iteration , preceded by compare ( cmpl ) and add ( addl ) instructions.
In this case, the "jump" instruction clearly executes loop control flow by directly addressing iteration , but "jumps" can be indirect, addressing code via an address stored in memory. These indirect "jumps" make it difficult to map assembly instructions to the source code. Some other features of compiler optimization also make this mapping difficult, for example tail call optimization.
Tail call optimization
A tail call is a sub-routine call made immediately before a function returns. Calls have high overheads as they add a new stack frame to the call stack. Tail calls can be replaced with “jumps”, and compiler optimization eliminates tail calls to minimize overhead; see the example below:
int state;
int (* func) (void);
int state_machine (void) {
switch (state) {
case 1: state = 2; return 0;
case 2: state = 3; return 0;
default: return func ();
}
}
A compiler eliminates the high-overhead tail call by replacing the expression with a “jump” to the func sub-routine:
state_machine: cmpl $2, state jbe switch case_default: movl func, %eax jmp *%eax /* This jump originates from a tail call */ switch: movl state, %eax movl jump_table(,%eax,4), %eax jmp *%eax /* This jump originates from a switch statement */ case_1: movl $2, state ret case_2: movl $3, state ret .section .rodata jump_table: .long case_default .long case_1 .long case_2
The compiler optimized the call to func into a “jump”. You can see that the jmp *%eax “jump” instructions in this example are indirect, addressing data stored in memory rather than directly jumping to a code address. This can make it difficult to determine function boundaries, which are needed to determine WCET using RapiTime. It is trivial to see that func is stored in *%eax in this example, but this may not always be the case. To determine a call tree around “jump” instructions in object code, we make some assumptions.
We initially assume that “jump” instructions jump to another location within their parent function, as their origin is usually either a switch statement or a for or while loop. Optimized tail calls thus present a challenge; they appear identical to other types of “jump”, so we assume their destination is inside their parent function, but it may not be. In the code above, for example, one jump originates from a tail call to an external function, and the other from a switch statement.
To solve this problem, we parse trace data in two steps (see Figure 1 above). After parsing the trace once we reclassify instructions to recognize both the type and destination of a jump. The destination indicates whether the “jump” is to within or outside the parent function and lets us complete the call tree and loop nesting tree. Using the information from these trees, we can parse the trace again to determine WCET metrics.
Find out more
We hope you enjoyed this insight into the difficulties of WCET analysis on object code. Stay tuned for more details about object-code tracing in our SECT-AIR project.
In the meantime, if you would like to know more about timing analysis using RapiTime, visit our product page at /products/rapitime.
DO-178C webinars
White papers

Mitigation of interference in multicore processors for A(M)C 20-193

Developing DO-178C and ED-12C-certifiable multicore software

Efficient Verification Through the DO-178C Life Cycle

A Commercial Solution for Safety-Critical Multicore Timing Analysis