 Skip to main content
Skip to main content
 Rapita System Announces New Distribution Partnership with COONTEC
Rapita System Announces New Distribution Partnership with COONTEC
 Rapita partners with Asterios Technologies to deliver solutions in multicore certification
Rapita partners with Asterios Technologies to deliver solutions in multicore certification
 SAIF Autonomy to use RVS to verify their groundbreaking AI platform
SAIF Autonomy to use RVS to verify their groundbreaking AI platform
 What does AMACC Rev B mean for multicore certification?
What does AMACC Rev B mean for multicore certification?
 How emulation can reduce avionics verification costs: Sim68020
How emulation can reduce avionics verification costs: Sim68020
 Multicore timing analysis: to instrument or not to instrument
Multicore timing analysis: to instrument or not to instrument
 How to certify multicore processors - what is everyone asking?
How to certify multicore processors - what is everyone asking?
 Certifying Unmanned Aircraft Systems
Certifying Unmanned Aircraft Systems
 DO-278A Guidance: Introduction to RTCA DO-278 approval
DO-278A Guidance: Introduction to RTCA DO-278 approval
 ISO 26262
ISO 26262
 Data Coupling & Control Coupling
Data Coupling & Control Coupling
 DASC 2025
DASC 2025
 DO-178C Multicore In-person Training (Fort Worth, TX)
DO-178C Multicore In-person Training (Fort Worth, TX)
 DO-178C Multicore In-person Training (Toulouse)
DO-178C Multicore In-person Training (Toulouse)
 HISC 2025
HISC 2025











Solving the challenges of multicore timing analysis
We help you:
- Optimize multicore code for timing
- Evaluate multicore hardware
- Ensure freedom from interference
- Produce DO-178C/CAST-32A evidence
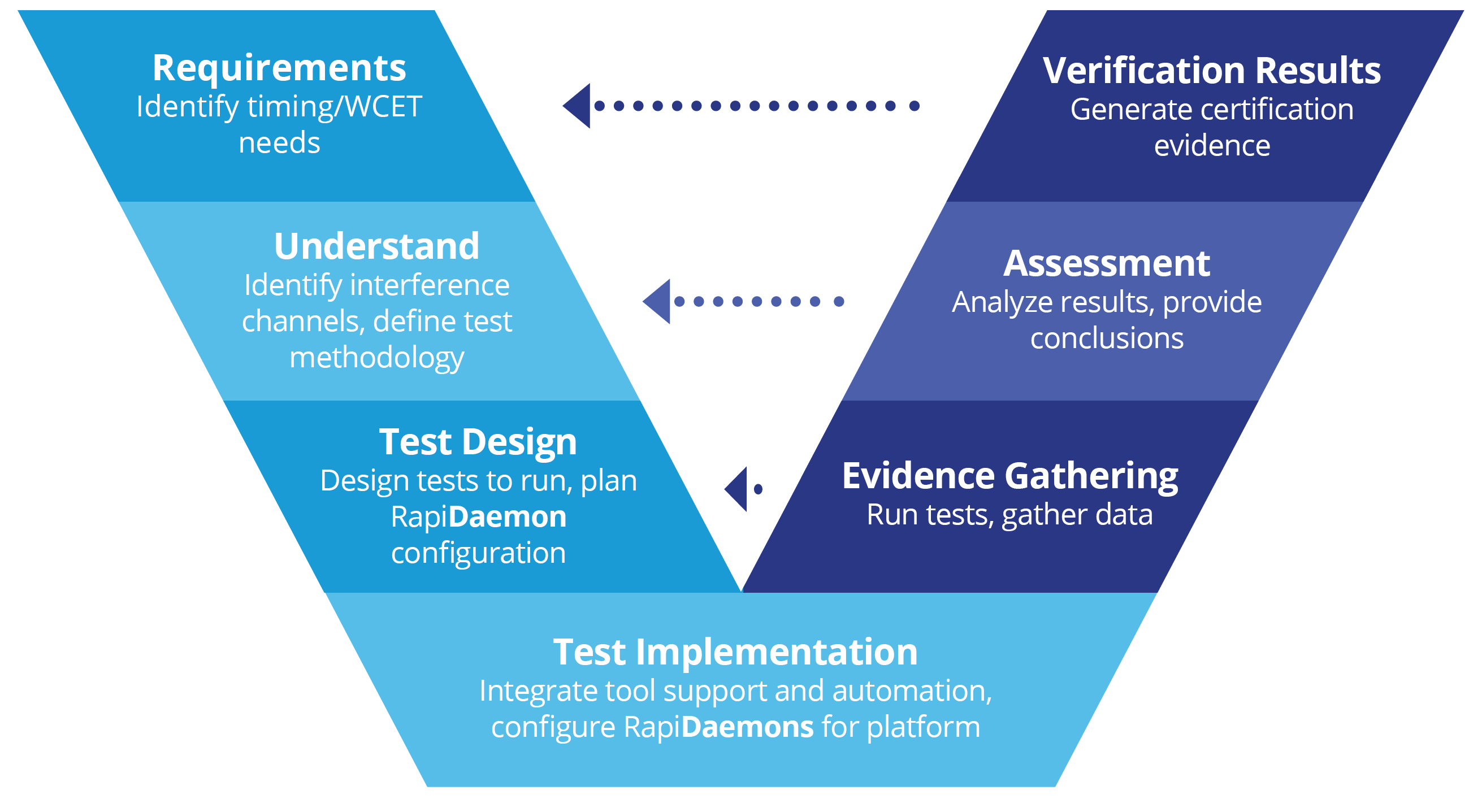
Our approach
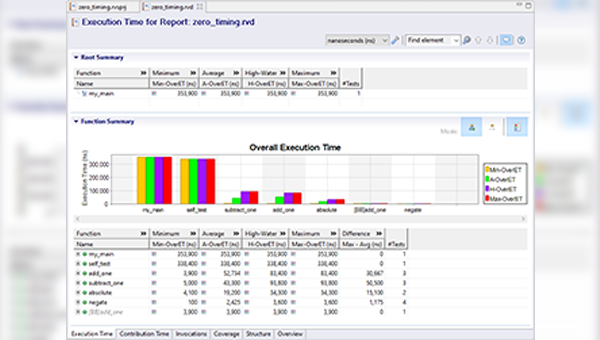
Our unique solution to multicore timing analysis produces execution time evidence for multicore systems.
By following a V-model process, our engineers investigate multicore systems and produce evidence about multicore timing behavior. Our industry-leading tooling, including our unique RapiDaemon technology (which generates interference during tests), reduces analysis effort through automation.
Our approach has been designed to support projects within the AC 20-193, AMC 20-193 and ISO 26262 contexts.
Working with us
We recognize that each test project is different, and work with you to meet your needs.
We run testing activities on-site, at our headquarters in the UK, and at Rapita Systems, Inc. in Novi, Michigan. We can support projects with UK / US EYES ONLY requirements.
We can answer multicore timing questions and produce evidence for you, or implement a method and provide training so you can do so yourself.
RapiDaemons are specialized microbenchmark programs that generate contention on hardware resources such as buses, caches and GPUs.
They support multicore timing analysis by generating contention while multicore timing tests are run, allowing interference effects to be considered while performing the analysis.
Each RapiDaemon applies contention to a specific hardware resource on a specific hardware architecture, either matching a desired level of contention or maximizing contention on the resource.
Compatibility
We can analyze almost all multicore hardware architectures. See below for a list of components of multicore systems that we have analyzed.
Architectures
We have already analyzed the architectures below and can analyze architectures not on this list:
SoC | Cores |
|---|---|
Infineon® AURIX™ | Tricore™ |
NVIDIA® Xavier™ | Carmel Armv8 |
NXP® i.MX 8 | Arm® Cortex®-A53 |
NXP® LS1048A | Arm® Cortex®-A53 |
NXP® LS1088M | Arm® Cortex®-A53 |
NXP® LX2160A | Arm® Cortex®-A72 |
NXP® MPC5777C | PowerPC® e200, PowerPC® e200Z7 |
NXP® P2041 | PowerPC® e500mc |
NXP® T1040/2 | PowerPC® e5500 |
NXP® T2080/1 | PowerPC® e6500 |
TI Keystone™ K2L | Arm® Cortex®-A15 |
TI TMS320F28388D | TI C28x |
Xilinx® Ultrascale+® Zynq MPSoC | Arm® Cortex®-A53, Arm® Cortex-R5 |
Xilinx® Ultrascale+® Zynq RFSoC | Arm® Cortex®-A53, Arm® Cortex-R5 |
If your architecture is not on the list above, contact us.
RTOSs
We have already analyzed the RTOSs below and can analyze RTOSs not on this list:
RTOS |
|---|
Bare metal |
Blackberry® QNX™ |
DDC-I Deos™ |
Green Hills® INTEGRITY® |
KRONO-SAFE® ASTERIOS® |
Lynx Software Technologies LynxSecure® |
SYSGO PikeOS® |
Vector MICROSAR |
Wind River Helix®/VxWorks® |
Custom RTOSs |
If your RTOS is not on the list above, contact us.
Boards
We have already analyzed boards from the manufacturers below and can analyze boards from manufacturers not on this list:
Board Manufacturer |
|---|
Abaco™ |
Curtiss-Wright® |
Mercury Systems® |
North Atlantic Industries™ |
NXP® |
Texas Instruments® |
Xilinx® |
If your board manufacturer is not on the list above, contact us.
Middleware
We have already analyzed middleware from the suppliers on the list below and can analyze middleware from suppliers not on this list:
Middleware Supplier |
|---|
CoreAVI® |
GateWare Communications™ |
Presagis® |
Richland Technologies™ |
If your middleware manufacturer is not on the list above, contact us.
Frequently asked questions
-
What is multicore timing analysis?
When developing safety-critical applications to DO-178C, AC 20-193, AMC 20-193 and CAST-32A guidelines or ISO 26262 standards, there are special requirements for using multicore processors. Evidence must be produced to demonstrate that software operates within its timing deadlines.
The goal of multicore timing analysis is to produce execution time evidence for these complex systems. In multicore processors, multiple cores compete for the same shared resources, resulting in potential interference channels that can affect execution time. MACH178 and Rapita's Multicore Timing Solution account for interference to produce robust execution time evidence in multicore systems.
-
Can your solution help me with certification aspects of my multicore project?
Yes. Our solution can be used to produce timing evidence needed to satisfy DO-178C objectives (in line with AC 20-193, AMC 20-193 and CAST-32A guidance), and ISO 26262 standards.
-
What is an interference channel?
In AMC 20-193, the official guidance document for multicore aspects of certification for ED-12C projects, an interference channel is defined as "a platform property that may cause interference between software applications or tasks". This definition can be applied to a range of ‘platform properties’, including thermal factors etc.
Of these interference channels, interference caused by the sharing of certain resources in multicore systems is one of the most significant in terms of execution times. Interference based on shared resources may occur in multicore systems when multiple cores simultaneously compete for use of shared resources such as buses, caches and main memory.
Rapita’s solutions for multicore timing analysis analyze the effects of this type of interference channel.
A very simple example of a shared resource interference channel is shown below:
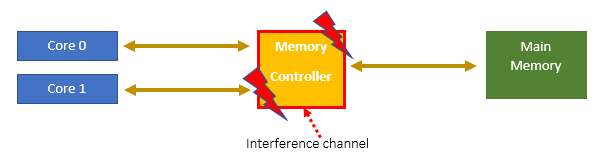
In this simplified example, tasks running independently on the two cores may need to access main memory simultaneously via the memory controller. These accesses can interfere with each other, potentially degrading system performance.
-
Why can I trust Rapita's Multicore worst-case execution time statistics?
Rapita have been providing execution time analysis services and tooling since 2004.
RapiTime, part of the Rapita Verification Suite (RVS), is the timing analysis component of MACH178 and the Multicore Timing Solution. Our customers have qualified RapiTime on several DO178C DAL A projects where it has been successfully used to generate certification evidence by some of the most well-known aerospace companies in the world. See our Case Studies.
As well as providing a mature tool chain, we support you in ensuring that your test data is good enough, so that the timing information you generate from the target is reliable.
Our RapiDaemons are configured and tested (see the FAQ: ‘configuring and porting’) to ensure that they behave as expected on your multicore platform.
We also assess available observability channels as part of Platform Analysis. This primarily applies to the use of Hardware Event Monitors, where we assess their accuracy and usefulness for obtaining meaningful insights into the system under observation.
-
Why can't I do my own multicore timing analysis and certification?
It is possible for companies to perform multicore timing analysis internally, but it is a highly complex undertaking which is very costly in terms of budget and effort. Anecdotally, one of our customers reported that it took them five years and a budget in the millions of dollars to analyze one specific platform.
MACH178 and our Multicore Timing Solution are typically delivered as a turn-key solution, from initial system analysis and configuration all the way through to providing evidence for certification.
-
If my RTOS vendor says they provide robust partitioning, why do I need Rapita?
RTOS vendors may provide partitioning mechanisms for their multicore processors, but these do not guarantee the complete elimination of multicore interference. Instead, they are designed to provide an upper limit on interference, sometimes at the expense of average-case performance.
In aerospace, these partitioning mechanisms may be referred to as ‘robust partitioning’. The multicore guidance in AC 20-193, AMC 20-193 and CAST-32A identify allowances for some of the objectives if you have robust partitioning in place, but it is still necessary to verify that the partitioning is as robust as it is claimed to be.
From a certification standpoint, regardless of the methodology behind the RTOS vendor’s approach to eliminating interference, the effectiveness of the technology needs to be verified.
-
Can you help me optimize the configuration of my multicore system?
Yes – our approach can be used to get an in-depth understanding of how sensitive software can be to other software. For example:
- Task 1 executes acceptably in isolation and with most other tasks, but if it executes simultaneously with Task 127, its function X takes 10 times as long to return.
- This intelligence can feed into system integration activities to ensure that function X can never execute at the same time as Task 127.
The information from this type of analysis can also provide insights into potential improvements to the implementation of the two tasks. Sensitive tasks are not always the guilty party: other tasks can be overly aggressive and cause delays in the rest of the system.
-
How do you ensure that worst-case execution time metrics are not excessively pessimistic?
For safety reasons, WCET will always be somewhat pessimistic. However, techniques that work well for single-core systems risk generating a WCET that is unreasonably large when applied to multicore systems, because the effects of contention can become disproportionate. The objective, therefore, is to calculate a value that is plausible and useful, without being optimistic. Optimism in relation to WCET is inherently unsafe.
It is not enough to identify how sensitive an application’s tasks are to different types and levels of interference; it is also necessary to understand what degree of interference a task may suffer in reality. It is possible to lessen the pessimism in WCET analysis by viewing the processor under observation through this paradigm.
The degree to which we can reduce pessimism is dependent on how effectively we can analyze the system. Factors influencing this include:
- The overhead of the tracing mechanism (which affects depth of instrumentation)
- The availability and reliability of hardware event monitors
- The availability of information regarding other tasks executing on the system
- The quality of tests that exercise the code
-
Can you quantify our cache partitioning to maximize our performance?
Cache partitioning is all about predictability, not performance. Your code may execute faster on average without cache partitioning, but it probably wouldn't be as predictable and could be quite sensitive to other software components executing in parallel.
Cache partitioning aims to remove all the sensitivity to other tasks sharing the caches, thus making your task more predictable – but potentially at the expense of overall performance. In critical systems, predictability is of far greater importance than performance.
Rapita’s solution for multicore timing analysis can be used to exercise cache partitioning mechanisms by analyzing any shared – and usually undocumented – structures internal to the caches.
-
Are there any constraints on the application scheduling, supervisor, or hypervisor?
To analyze how a specific task is affected by contention on a specific resource, we need to be able to synchronize the execution of the task with the execution of RapiDaemons (the applications that generate contention on the resource).
Usually, it is highly desirable to have RTOS/HV support for enabling user-level access to hardware event monitors. Context switch information is also very valuable when performing multicore timing analysis.
-
Can you analyze systems using asymmetric multiprocessing?
Yes. Our solution makes it easy to specify the core on which you run your tests, and the level of resource contention to apply from each other core in the system.
We can also analyze systems that use non-synchronized clocks such as those often present in AMP platforms by using the RTBx to timestamp data.
-
How many hardware event monitors can you collect values from per test?
The maximum number of hardware event monitors we can collect values from depends on the performance monitoring unit(s) (or equivalent) on the hardware. An ARM A53, for example, lets us collect at least 30 metrics, but only access 6 in a single test. By running tests multiple times, however, we could collect all 30 metrics.
-
Why don't you have a tool that automates multicore timing analysis?
Developing a one-button tool solution for multicore timing analysis would be impossible. This is because interference, which can have a huge impact on a task’s execution time, must be taken into account when analyzing multicore timing behavior.
Analyzing interference effects is a difficult challenge that cannot be automatically solved through a software-only solution. Using approaches developed for timing analysis of single-core systems would result in a high level of pessimism, as it would assume that the highest level of interference possible is feasible, while this is almost never the case.
-
Which metrics can you collect from my multicore platform?
It is possible to collect a range of metrics by instrumenting your source code with the Rapita Verification Suite (RVS), including a range of execution time metrics:
- RapiTime: high-water mark and maximum execution times
- RapiTask: scheduling metrics such as periodicity, separation, fragmentation and core migration
It is also possible to collect information on events in your hardware using hardware event monitors. The information we can collect depends on the performance monitoring unit(s) (or equivalent) of your system, but typically includes events such as L2 cache accesses, bus accesses, memory accesses and instructions executed. We can also collect information about operating system activity such as task switching and interrupt handling via event tracing or hooks.
-
Do you test the validity of hardware event monitors?
Yes, we formally test and assess the accuracy of hardware event monitors to ensure the validity of results we collect for the software under analysis.
-
Why should I use Rapita's solution?
Rapita Systems are uniquely positioned to offer the combination of expertise and tools required to effectively perform multicore timing analysis.
Whilst the challenge of certifying multicore systems for safety-critical applications is a relatively new one for the industry as a whole, we have been researching this area for over a decade. Rapita are working with key industry stakeholders, including major chip-manufacturers like NXP, to support them in refining the evidence required to satisfy certification authorities.
Rapita have extensive experience in providing software verification solutions for some of the best-known aerospace and automotive companies in the world. For example, BAE Systems used RapiTime (one of the tools in our Multicore Timing Solution) to identify worst-case execution time optimizations for the Mission Control Computer on their Hawk Trainer jet.
See more of our Case Studies.
-
What components are involved in your multicore timing analysis solution?
Our multicore timing analysis solution comprises three components: a process, tool automation, and services.
Our multicore timing analysis process is a V-model process that we developed in line with DO-178, AC 20-193, AMC 20-193 and CAST-32A. It follows a requirements-based testing approach that focuses on identifying and quantifying interference channels on multicore platforms.
The tools we have developed let us apply tests to multicore hardware (RapiTest) and collect timing data (RapiTime) and other metrics such as scheduling metrics (RapiTask) from them. We use RapiDaemons to create a configurable degree of traffic on shared hardware resources during tests, so we can analyze the impact of this on the application’s timing behavior.
Our multicore timing analysis services include tool integration, porting RapiDaemons, performing timing analysis, identifying interference channels, and others depending on customer needs.
-
What is Rapita's approach to multicore timing analysis?
By following a V-model process, our engineers investigate multicore systems and produce evidence about multicore timing behavior. Our approach has been designed to support projects within the DO-178C (AC 20-193, AMC 20-193 and CAST-32A) and ISO 26262 contexts.
You can see an example workflow of how Rapita approaches multicore timing analysis in our White Paper.
-
Which hardware architectures can you analyze?
We can analyze almost all hardware architectures. Our engineers work with you to determine the optimal strategy for integrating our RVS tools with your target, including hardware characterization and design considerations to best fit the hardware you're using.
To work with an architecture that is new to us, we first identify which metrics we can collect from the hardware, then adapt RapiDaemons for the architecture and implement a strategy to collect data from it.
For a list of multicore architectures, RTOSs, boards and middleware we've worked with, see our compatibility page.
-
Is there a standard list of interference channels that I should test?
There is no standard list that fits all platforms. Some interference channels can be more common than others, such as the ones related to the memory hierarchy (i.e. caches and main memory). The identification of interference channels (for which we provide a service) is an important activity that identifies the interference channels whose impact on the system’s timing behavior must be assessed.
-
How long does it take to comprehensively analyze the interference channels present in multicore platforms?
The length of time needed to comprehensively analyze interference channels is typically between 2 and 12 months, but this duration depends heavily on the scope of the analysis, the complexity of the system, and whether we have already analyzed a similar platform or not. Our solution includes an initial pilot phase in which we study the system and estimate the amount of time needed for subsequent phases, including analysis of interference channels.
-
Have you performed platform analysis for my multicore platform?
Some of the multicore systems that we’ve worked with are listed in our FAQ “Which hardware architectures can you analyze?”.
If we have already worked on a similar multicore platform to yours, it may take less time to perform platform analysis for your platform.
-
Do you support the analysis of GPU-based architectures for multicore timing behavior?
Yes. We have run projects analyzing the Nvidia Xavier AGX (CUDA) and AMD’s Embedded Radeon E9171 GPU (featuring the CoreAVI Vulkan SC driver).
-
Is cache partitioning helpful or harmful to multicore timing performance?
This depends on the performance requirements of the platform and the hosted software.
The primary benefit of cache partitioning is that it provides protection from one core/partition evicting another. There are two broad approaches to achieve this:
- Hardware: In hardware, the processor has built in support for partitioning the cache, allocating each core in the system its own area that it can use. This is supported on the T2080, for example (see e6500 TRM section 2.12.4).
- Software: In set-associative caches, the location in cache that each block of memory may be loaded to is known. Using techniques like cache colouring, the software is placed in specific memory blocks in such a way that it is ensured that there will be no two cores/partitions that can end up using the same section of the cache.
In terms of execution time, the prime benefit of cache partitioning is typically a significant reduction in the variability i.e. a comparison with and without cache partitioning would indicate that execution times have a greater spread when there is cross-core interference present. This can be a valuable contribution towards the claim for robust partitioning.
The downside of cache partitioning is that, depending on the nature of the hosted application, it can have a significant impact on performance on the average case and even on the worst-case execution time. The reason for this is that each core/partition now has a smaller section of the cache to work with; if it no longer fits into the cache, then it will see an increased cache miss rate which has a direct impact on execution time. Whether this is acceptable should be carefully tested and evaluated.
A common misconception for shared cache partitioning is that it eliminates the effects of interference from shared L2 caches. Depending on the hardware, the shared caches can have shared buffers/queues that are not part of the partitioning. Therefore, even though the interference due to one core or partition evicting another can approach zero, the increase in cache misses can cause slowdowns due to contention on these shared internal structures.
For an IMA platform, it is recommended that the effectiveness of cache partitioning is evaluated empirically. Specifically, perform experiments/tests where the cache partitioning is enabled where RapiDaemons targeting the L2 cache generate interference, and compare against equivalent interference scenarios where the partitioning is disabled. It is quite likely that there will be observed slowdowns in the average case, and potentially also in the worst-case. The results from this analysis could be converted into constraints for the partition developers and integrators. For example "hosted IMA partitions on any core may not exceed X number of accesses outside L1 cache over a time window of Y nanoseconds".
-
What is Rapita's Multicore Timing Solution?
Our Multicore Timing Solution produces metrics to quantify and verify the timing behavior of software run on multicore systems while taking into account the effects of interference between different cores and tasks in the system.
Using a requirements-based testing approach, it combines expert engineering knowledge, RapiDaemons software from groundbreaking academic research and industry-leading tool automation support to provide a unique solution that meets the needs of multicore system adoption.
-
How does RVS support multicore timing analysis?
RVS, Rapita's verification toolsuite, supports multicore timing analysis by letting you create and run multicore timing tests, automatically capture verification results as these tests run on your multicore platform, efficiently analyze collected results, and generate compliance evidence when your analysis is complete.
RVS includes a range of features that support multicore timing analysis, including:
- RVS supports the collection of a range of metrics during testing, including execution time results and values from hardware event monitors on your platform, such as the number of cache hits and cache misses.
- RVS makes it easy to view and analyze multicore timing results by letting you filter your results on the performance metrics and tests you want to see and letting you select a baseline against which to compare your results.
- RVS lets you generate custom exports to provide compliance evidence. Custom exports reduce your documentation effort by automatically pulling in results from your reports and automatically reporting pass/fail status based on your success criteria.
- RapiTime lets you automatically merge timing results collected during multicore timing analysis into a single report. This lets you collect and analyze results from multiple test runs, multiple builds and multiple time points, and supports running results on multiple test rigs.
-
How do RapiDaemons support multicore timing analysis?
RapiDaemons support multicore timing analysis by allowing the timing behavior of a multicore platform to be analyzed under different levels of resource contention. By stressing specific shared resources at known levels, they support precise analysis.
For more information on RapiDaemons, see the RapiDaemons web page.
-
Can statistical modeling approaches be used to provide support for multicore timing measurements?
In general, statistical modeling approaches such as Queueing Theory are not applicable to timing analysis of multicore software as software timing behavior does not fit standard statistical assumptions. While the analysis of multicore timing results is based on a representation of the measured real distribution of execution times, it would not be correct to try to estimate averages and standard distributions from the data because we cannot assume that it follows any standard statistical distribution without experimental evidence to show this.
In some cases, software timing behavior may fit standard statistical assumptions, but this is the exception rather than the rule and must be proven before relying on results from statistical modeling.





{kind=link}
{kind=link}