Skip to main content
Skip to main content
 RVS 3.24 accelerates multicore software verification
RVS 3.24 accelerates multicore software verification
 Rapita Systems and Avionyx Announce Strategic Partnership to Offer Best-in-class Avionics Solutions
Rapita Systems and Avionyx Announce Strategic Partnership to Offer Best-in-class Avionics Solutions
 Rapita System Announces New Distribution Partnership with COONTEC
Rapita System Announces New Distribution Partnership with COONTEC
 RVS gets a new timing analysis engine
RVS gets a new timing analysis engine
 How to measure stack usage through stack painting with RapiTest
How to measure stack usage through stack painting with RapiTest
 What does AMACC Rev B mean for multicore certification?
What does AMACC Rev B mean for multicore certification?
 How emulation can reduce avionics verification costs: Sim68020
How emulation can reduce avionics verification costs: Sim68020
 How to achieve multicore DO-178C certification with Rapita Systems
How to achieve multicore DO-178C certification with Rapita Systems
 How to achieve DO-178C certification with Rapita Systems
How to achieve DO-178C certification with Rapita Systems
 Certifying Unmanned Aircraft Systems
Certifying Unmanned Aircraft Systems
 DO-278A Guidance: Introduction to RTCA DO-278 approval
DO-278A Guidance: Introduction to RTCA DO-278 approval
 Test what you fly - Real code, Real Conditions Webinar
Test what you fly - Real code, Real Conditions Webinar
 Avionics Certification Q&A: CERT TALK
Avionics Certification Q&A: CERT TALK
 XPONENTIAL 2026
XPONENTIAL 2026
 DO-178C Multicore In-person Training (Heathrow)
DO-178C Multicore In-person Training (Heathrow)










Because of their complexity, most modern systems are reliant on scheduling algorithms for efficient multitasking and multiplexing. Invariably these algorithms implement compromises based on specific objectives such as meeting deadlines. This blog post looks at two tasking models which implement different compromises depending on the objectives set by the system user: these models are called “co-operative” and “pre-emptive”.
How the task scheduling world is changing
In the real-time world, older systems used to operate in a fairly simple stand-alone mode, e.g.:
System Initialise loop forever Read Inputs Process Data Drive Outputs end loop
However, the increasing complexity and functionality of systems required more responsive and flexible solutions. Initially this was implemented via use of such run time kernels such as VRTX – which is still used for example in the Hubble Space Telescope – but has now been extended to such environments as Windows and Linux.
The requirement for real-time systems is to provide rapid response to external events, for example, when a power plant sensor indicates an over-temperature condition, the cooling process should be instigated fairly rapidly. The standard unit of scheduling is commonly referred to as a task. It is the job of the scheduler to run these tasks as and when required.
A quick guide to task scheduling
A task may generally take one of the following states:
| Inactive | One that has not yet been started, or has been shut down. For example, some tasks are usually started by a system initialisation process. These may complete and shut down, or continue forever. These tasks may also start other tasks |
| Active | Eligible to run – i.e. not blocked or inactive but another task is executing |
| Blocked | Waiting on a stimulus such as a semaphore or a queue item |
| Executing | The executing task has the CPU |
Different systems may use different terms – task = process = activity etc. – but mapping is usually fairly obvious. Tasks may also have differing priorities. These may be statically or dynamically allocated, but the scheduler should always run the highest priority eligible task. The IT world cannot agree whether high to low is (say) 1 to 255, or low to high is 1 to 255 – that’s life!
Co-operative Scheduling
Once started, a task within a co-operative scheduling system will continue to run until it relinquishes control. This is usually at its synchronisation point. Typically a task could:
loop forever Read Queue Process Data/Update Outputs end loop
where the Read Queue is a synchronisation point. The call will enable the scheduler which will then check the states of all the tasks within the system and schedule the highest priority ready task. Algorithms vary slightly, for example a task make be allowed to run until all its inputs are consumed or a “round robin” scheduling may be implemented whereby each task of equal priority is run once and is then placed at the end of the active task queue. If multiple priorities are supported then there will be many queues – one for each active level, which have to be monitored.
If a task has no more data to process it will be removed from the active queue and placed in a blocked state.
Tasks will be unblocked whenever an event occurs which creates a need for that task to run. This may be an external event e.g. receipt of data packed from another system, an interrupt caused by a sensor detecting a pre-programmed state change or an internal event such as another task setting a semaphore / queuing / a data packet.
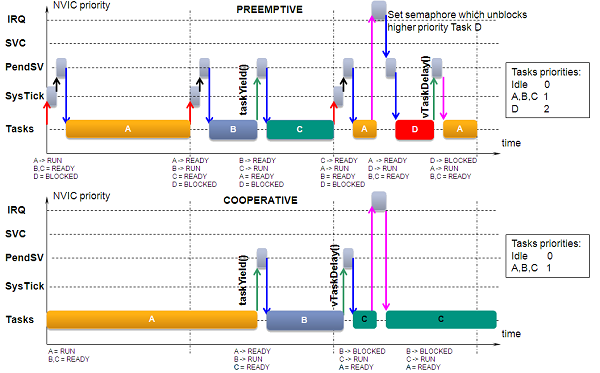
Pre-emptive Scheduling
Pre-emptive scheduling retains many of the features described above e.g. tasks, task states / queues / priorities etc. However there is one very important difference. In a co-operative system a task will continue until it explicitly relinquishes control of the CPU. In a pre-emptive model tasks can be forcibly suspended. This is instigated by an interrupt on the CPU.
These interrupts may be from external systems as above or possibly from the system clock. The difference here is that the scheduler is invoked following one of these system events. If a sensor detects an alarm condition, the input circuitry can generate an interrupt to the CPU.
The Interrupt Service Routine (ISR) will be called immediately and may perform some suitable action such as setting a semaphore. However, instead of the ISR returning to the interrupted task, the scheduler is executed. The highest priority ready task will then be enabled which may or may not be an interrupted task. It can be seen that this allows systems to more rapidly respond to real-time events in applications such as avionics, where any response delay may have serious effects. Additionally, clock interrupts may also invoke rescheduling, for example when a high priority task timer expires.
There are some implications when using pre-emption. Overheads involved with interrupts and tasking will almost inevitably increase, and care must be taken to ensure that time critical data retains its integrity.
Tracking and Tracing
As processors get more powerful and applications more complex, monitoring the behaviour of systems and their component tasks gets more difficult. Rapita Systems can assist both at a system level and a tasking level.
The application of RapiTask gives an excellent visualisation of the tasking and scheduling behaviour of a system and can assist tracking down tasking issues. An example of this is given in a previous blog (on the Mars Pathfinder).
In addition, RapiTime includes powerful filters which allow individual task tracing data sets to be examined and detailed timing and performance data for that task, isolating that task and ignoring other activity.
DO-178C webinars
White papers

Mitigation of interference in multicore processors for A(M)C 20-193

Developing DO-178C and ED-12C-certifiable multicore software

Efficient Verification Through the DO-178C Life Cycle

A Commercial Solution for Safety-Critical Multicore Timing Analysis